End of document------
--------GO Up to HOME Page --- Revised July 31 2013
-------------------------------------------------------
NEW MATERIAL
My Theory of MONOPOLES being basis of Universe: A Classical model of the Aether based on paired Monopoles.
 1/2019 note---
If you are not aware why almost every computer in the world
1/2019 note---
If you are not aware why almost every computer in the world
was obsolesed by Meltdown and Spetre security memory ERROR families.
These memory bleed thru leaks are caused by chip and firmware interpretations by designer's from different HW and SW domains, their assumptions were different.
Throw in the "flywheel-cpu effient" mentality of most Engineers, a perfect anti-Ven diagram is created whose holes extend thru time and space that will always allow memory leakage under given conditions.
The Design of this paper would not be affected because it shared cpu-cores by design;
being more optimal was a much low priority than being more secure.
Here is a report of current status/efforts by Intel's Elite team.
Throughout 2018, researchers inside and outside Intel continued to find exploitable weaknesses related to Meltdown and Spectre class of "speculative execution" vulnerabilities. Fixing many of them takes not just software patches, but conceptually rethinking how processors are made.
From a report: At the center of these efforts for Intel is STORM, the company's strategic offensive research and mitigation group, a team of hackers from around the world tasked with heading off next-generation security threats. Reacting to speculative execution vulnerabilities in particular has taken extensive collaboration among product development teams, legacy architecture groups, outreach and communications departments to coordinate response, and security-focused research groups at Intel.
STORM has been at the heart of the technical side. "With Meltdown and Spectre we were very aggressive with how we approached this problem," says Dhinesh Manoharan, who heads Intel's offensive security research division, which includes STORM. "The amount of products that we needed to deal with and address and the pace in which we did this -- we set a really high bar."
Intel's offensive security research team comprises about 60 people who focus on proactive security testing and in-depth investigations. STORM is a subset, about a dozen people who specifically work on prototyping exploits to show their practical impact. They help shed light on how far a vulnerability really extends, while also pointing to potential mitigations. The strategy helped them catch as many variants as possible of the speculative execution vulnerabilities that emerged in a slow trickle throughout 2018.
"Every time a new state of the art capability or attack is discovered we need to keep tracking it, doing work on it, and making sure that our technologies are still resilient," says Rodrigo Branco, who heads STORM. "It was no different for Spectre and Meltdown. The only difference in that case is the size, because it also affected other companies and the industry as a whole."
MAY2019 Phoronix has conducted a series of tests to show just how much the Spectre and Meltdown patches have impacted the raw performance of Intel and AMD CPUs. While the patches have resulted in performance decreases across the board, ranging from virtually nothing to significant depending on the application, it appears that Intel received the short end of the stick as its CPUs have been hit five times harder than AMD, according to ExtremeTech. From the report:
The collective impact of enabling all patches is not a positive for Intel. While the impacts vary tremendously from virtually nothing to significant on an application-by-application level, the collective whack is about 15-16 percent on all Intel CPUs without Hyper-Threading disabled. Disabling increases the overall performance impact to 20 percent (for the 7980XE), 24.8 percent (8700K) and 20.5 percent (6800K).
The AMD CPUs are not tested with HT disabled, because disabling SMT isn't a required fix for the situation on AMD chips, but the cumulative impact of the decline is much smaller. AMD loses ~3 percent with all fixes enabled. The impact of these changes is enough to change the relative performance weighting between the tested solutions. With no fixes applied, across its entire test suite, the CPU performance ranking is (from fastest to slowest): 7980XE (288), 8700K (271), 2990WX (245), 2700X (219), 6800K. (200). With the full suite of mitigations enabled, the CPU performance ranking is (from fastest to slowest): 2990WX (238), 7980XE (231), 2700X (213), 8700K (204), 6800K (159).
In closing, ExtremeTech writes: "AMD, in other words, now leads the aggregate performance metrics, moving from 3rd and 4th to 1st and 3rd. This isn't the same as winning every test, and since the degree to which each test responds to these changes varies, you can't claim that the 2990WX is now across-the-board faster than the 7980XE in the Phoronix benchmark suite. It isn't. But the cumulative impact of these patches could result in more tests where Intel and AMD switch rankings as a result of performance impacts that only hit one vendor."
Nov 2019 -- The Zombieload vulnerability disclosed earlier this year in May has a second variant that also works against more recent Intel processors, not just older ones, including Cascade Lake, Intel's latest line of high-end CPUs -- initially thought to have been unaffected. From a report:
Intel is releasing microcode (CPU firmware) updates today to address this new Zombieload attack variant, as part of its monthly Patch Tuesday -- known as the Intel Platform Update (IPU) process. Back in May, two teams of academics disclosed a new batch of vulnerabilities that impacted Intel CPUs. Collectively known as MDS attacks, these are security flaws in the same class as Meltdown, Spectre, and Foreshadow. The attacks rely on taking advantage of the speculative execution process, which is an optimization technique that Intel added to its CPUs to improve data processing speeds and performance.
Vulnerabilities like Meltdown, Spectre, and Foreshadow, showed that the speculative execution process was riddled with security holes. Disclosed in May, MDS attacks were just the latest line of vulnerabilities impacting speculative execution. They were different from the original Meltdown, Spectre, and Foreshadow bugs disclosed in 2018 because they attacked different areas of a CPU's speculative execution process.
Further reading: Flaw in Intel PMx driver gives 'near-omnipotent control over a victim device'.
New Title for this is OME for Operating Machine Environment
where four or more cpu-cores provide a "W=user & X=data" net environment!>
-------------------------------------------------------
--- Obsolete ---- POSOPIP: A Proposal for a new Computer Operating System with a
Distributed Security Architecture (DSA) that uses Multiple groups of three CPUs with a Service CPU.
Introduction & Background
The fundamentals of computing are always algorithm related.
Most solutions are a series of single sequence threads, usually derived from
our own serial human way of thinking. This results in both efficiency and difficulty when
using more than one CPU for most problems or applications.
Think of sharing a chore like cleaning a galley/kitchen three times a day,
among diverse groups; no solution is apparent if things are later dirty, missing or cracked,
it is difficult to figure out how, what, or who.
This is the state of most computer systems after they malfunction.
Currently, in multi-CPU systems, it is difficult to work with the dynamic nature
of separating tasks into threads which are then distributed almost randomly among
the CPUs depending on traffic loads. Debugging and error related problems sometimes
require both special hardware and software, usually beyond most user capabilities.
Even problems that lend themselves to parallel processing solutions are exotic
outside of the Graphics and Server arenas; far beyond common
commercial designs or average designer/programmer abilities. A new way of thinking about
processing and data flow is needed for this environment of CPU abundance,
if true Parallel benefits are to be achieved.
The AOS Solution: An Algorithm O/S or "Algorithm Operating System"
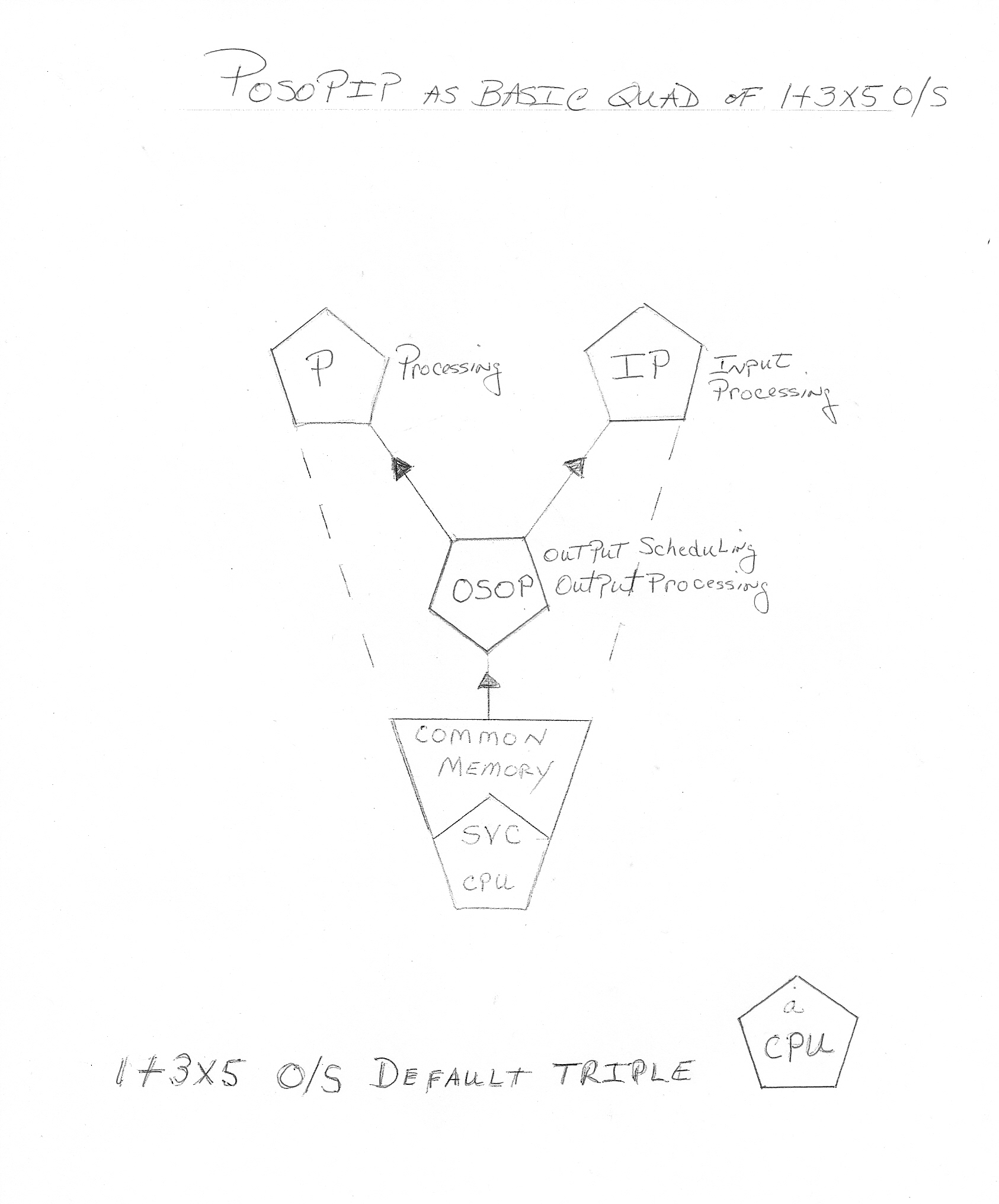
The classic three phase "Input-Processing-Output" sequence that is common
in almost all designs can be mapped directly to a three CPU implementation.
The three dedicated CPU types are the Input, Processing and Output CPU.
Expansion is then a times three manner; ie. 6,9,12,15 CPUs.
BYOS: Bring Your Own O/S
The local O/S is downloaded along with the application from your own library copy.
The OSOP cpu of the Posopip trio has a boot audit trail that verifies the integrity
of the system in real time. A JOB will not run in an unverified environment.
The Input CPU is dedicated to handling interrupts and data streams.
It queues results into common memory for the other two CPUs whose
loop scanners get, copy, and process the data in real time.
The Processing CPU runs in a simple non-interrupted loop mode
that can immediately process and verify data as soon as it is available.
O/S interaction is very limited or needed.
The Output CPU sends data out as soon as it is available by running in a loop
that scans for any work available. Again little O/S interaction is needed.
Summary
As Intel and AMD churn out larger multi-core chips each quarter, it becomes obvious that
there is no real Software [SW] able to use them in any CONSUMER noticeable way.
This design allows a new algorithm paradigm with many unique scalable features and powers.
The 1+3*5 design heralds a new era of system reliability and Reach; all with inherent security and integrity.
In comparisons with conventional multi-CPU systems, this design puts fidelity ahead
of efficiency to insure a reliable outcome every time.
Mostly idle CPU's are the norm in today's power hungry and costly server centers.
They are provisioned for peak work loads, so "Efficiency" practices were not necessarily
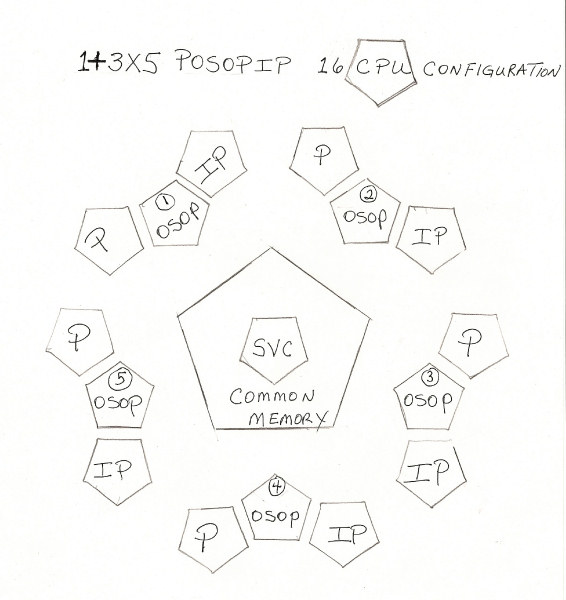
the best way to partition a sixteen CPU system; sixteen being the local geometry optimum core count.
Mister-Computer is seeking venture capital for a New Multi-CPU Operating System
This new and original multi-CPU Operating System has been designed for
4 to 16 AMD or INTEL type x86 cores, in a one plus three times five configuration;
with a literal name of 1+3*5 for the 16 CPU's.
The '1+3*5' is a very patentable design, as well as its literal numeric logo, being a natural Trademark.
Each of the 5 possible Nodes has 3 CPU's, that are shared among an active JOB(s).
The three CPU's form a Trinary named "POSOPIP"; with a dedicated CPU
for Input, Output and Processing. This makes algorithm design much simpler
in that, a Task is not fragmented in time or among other modules;
making several Secure authoritative modes possible!
The Service Computer, the one of 1+3*5, provides interrupt and I/O services for all CPU's.
The design runs under the real-time [r/t] QNX open source O/S
and is complete for most Medium to Higher levels.
Microsoft's current Windows8 and previous Vista product travails are ample demonstration that current Computer Industry
O/S Products and designs have reached several limits due to being overly complex,
too slow, size problems, and major cost and schedule overruns!
The "Mythical Man-month" is alive and well.
and illustrates why new types of Software Systems had large Impractical Cost and Time estimates!
* FAQ1: Why a new O/S? The current 2^32 address space limit was saturated
Newly available 2^64 Address offers over four billion times more reach.
* FAQ2: Why a new SMP Symmetric Multi-Processors usually have arbitrary sharing of resources,
including CPUs. Using the current "N + 1" scheme, forces each designer
to uniquely define and divide the loads or suffer some missed goals.
On average, 6 or more CPU's are usually idle; 10 or more are hardly ever all used,
unless the Job is locally fine-tuned to the desired state, accordingly.
* FAQ3: Who is designer? A 34+ year Computer Industry Vet; Univ of IL, 1965; B.Sci.
This not a Server design; it's a SuperUser design that should be judged by the obvious lack of
serious commercial competition and the current dead ends of uniprocessor based concepts.
eg. O/S slowness and Virtual-CPU schemes!
Having a dedicated CPU for Input, Processing and Output offers a simpler way
to partition tasks and reduce errors of omission, scheduling, and interference.
It has internal audit logs that insure adequate recovery, this is Posopip's bonus to its users.
Imagine nothing between you and your Data.
Table of Contents
* Obtain Office space
* Hire QNX consultants
* Hire a CTO to manage the 3 phases of development
Phase of Project
1 - Using a 4 CPU base system The 1+3*5 class O/S is system is developed and tested off-online ;
while its Ideas and algorithms are being PATENTED .
2 - Web community based promotion & development of an "SuperUser" class
with a MAC/Unix legacy backbone as part of a Uni-CPU Migration foundation.
Given this stable on-line base, enhancement requests, both free and paid, require staff increases.
3 - WWW.Fee-mail.org: An Ad friendly, Spam controlled network as a Future Equity product line.
A firm schedule of 2.5 to 4 years , for the three phases is envisioned. My choice for CTO is available, and familiar with the design.
All for a total investment of $3.6 million dollars, spread over the schedule; for a one-tenth equity stake.
This is pared down version of a company-confidential seven year development plan,
needing up to ten million dollars total.
Table of Contents
LEGACY API's via Unix and Apples's MAC paths of portability.
The QNX system will allow most Unix/MAC applications to be ported with minimum effort.
Linux does not allow its memory management system to be re-tuned
or to allow new user memory boundaries of gigabyte spans due to its old 'memory model';
it also did not allow users to remap the memory access and protection functions.
Therefore, it had eliminated itself as the SVC computer.
However running Linux in a three CPU frame under 1+3*5 will be a major goal of the WEB development phase.
DSA & SECURITY
In summary, 1+3*5 is a new way of designing algorithms that make security and accountability inherent.
Think of an application/JOB where both the 'designer' and User want
guaranteed results regardless of any runtime problems.
The 'P' or Processing CPU runs in a non-interruptabe loop until all user defined criteria are met.
In parallel, the 'IP' CPU is getting r/t interrupts
while the 'OSOP' CPU regulates output and maintains the JOB flow.
If the JOB's time budget is exceeded or JOB data results are insufficient,
the 'P' CPU posts the event so the 'OSOP' CPU can either re-schedule/retry/terminate appropriately.
The JOB finishes by having its results logged into common file memory
along with its time-stamped sequence of events.
The distribution of kernel functions and services among four computers
allows for strict security zone adherence due to redundant copies of important functions.
This forms the basis for the (DSA) Distributed Security Architecture itself.
*** Worst case: the JOB times out and it is retried or reported.
Think of an automated transfer system that has postage
as its entire cost of certifying 100% delivery of its many types of cargo.
All by using a common 1+3*5 'Posopip' infrastructure environment,
which contains its own copy of the Job supervisor as its local simple O/S.
Table of Contents
The Next Version CPU algorithm design is HERE!
The 1+3*5 O/S concepts are very flexible and patentable;
given its unique way of using 1 plus 3 to 15 CPU cores in this three by five manner!
Each team of three take on a JOB independent of the other trios;
unless specifically designed otherwise.
Think of five fingers, each having three of your designated attributes;
like sender, receiver and agent ,
or Debits, Credits and Bankers,
or two strangers through a proxy relay,
or a payer, payee and brokers,
or two litigants and a judge/arbiter.
In the 1+3*5 system you can do all FIVE at once.
Having an O/S with a r/t common environment, will allow a quantum leap in scope for most applications.
This heralds a new era of opportunities using this CPU Trio scheme in r/t.
For example, consider a 8 to 16 cpu system,
used as a two to five seat Command & Control system in a modern Naval warship.
Each seat of three CPU's would have direct access to its sensors and actuators
with the ability to respond quickly to any perceived threats independent of the actions of the other seats.
This design is growable in scale for more seats to control larger vessels.
Another application fit would be a 4 to 5 seat Control system for a modern Commercial Airliner.
1. Pilot seat, 2. Copilot seat, 3. Navigator seat, 4. Systems/support seat and 5. An optional Mission Specialist seat.
A new basis or new way to model/design Artificial Intelligence (AI) theories.
By using a CPU for the ID, EGO and the SuperEgo parts of the human mind;
many new ways to model AI goals become available.
Trinary: a generic ONE plus TWO CPU template !
"Trinary" is powerful syntax that will allow many current uni-CPU bound systems
to add two CPUs for enhanced work load sharing.
Posopip is the "default 1+ 2 CPU configuration template".
The 'OSOP' CPU is loaded first by the SVC CPU and it initializes the current JOB environment
by loading the 'P' and 'IP' CPU's accordingly with JOB parameters
and then starts the JOB by signaling the SVC CPU to allow input and output to begin.
Trinary: How uni-CPU algorithms can transition to the 1+3*5 O/S !
The Trinary concept allows a uni-CPU systems to be split in two; an Input CPU and an Output CPU.
The Uni-CPU design is divided into two parts; Input and its associated processing in a CPU
while Output and its associated processing in a second CPU.
The third CPU watches the other two to insure fidelity of function and performance
and to insure the data queues between them function correctly.
This important 1+3*5 attribute will en power the web development phase nicely,
as previously bound "CPU and api/dll programs" can be upgraded by adding two helper CPU's
to lighten the load of the master CPU. This will be possible under 1+3*5's Trinary syntax
along with the SVC CPU's coordinated services!
It would allow most uni-CPU Bound applications to at least double their throughput.
This will bring more than just hobby dollars into the 1+3*5 WEB community market place.
SVC CPU protocols as the basis of the 1+3*5 O/S !
Imagine trying to do three, six or even 15 related/independent/intense tasks
in your favorite environment leaving r/t out of the mix .
With "1+3*5 SVC CPU protocols", fifteen Jobs in r/t were normal,
as this was the standard deployment of the local 16 CPU environment .
Table of Contents
NOTES
There are several design features purposely omitted to enhance the over-view of 1+3*5 concepts.
1. Closing a JOB is immediate by today's desktop standards.
2. Threading is seldom needed due to dedicated CPUs.
3. There is NO virtual memory facility allowed outside of 1+3*5 rules.
4. Accurate statistics of how long programs and subroutines take to run will be available without special circumstances .
5. Each Posopip trio has Internal audit trails and redundant elements for r/t recovery options.
6. The 1+3*5 design has a Cloud like network with a IPv6 address space linking all internal and external data spaces.
7. The Goals of the Web community phase are to facilitate the migration of the MAC,
Windows and Linux systems to run under the 1+3*5 Architecture.
Additionally, generic uni-CPU expansion into a three CPU environment
will be facilitated with 1+3*5's "Trinary" syntax services .
Available White papers
#1 Why 1+3*5 is a great solution to the coming 4, 8 & 16 multi-core floods;
the next years will see many new multi-core systems and little SW to use them, besides the "N+1" model.
#2 Why a 3 CPU design leads to a straight forward and better way to program;
with guaranteed certifiable results [legally provable via time stamped audit traces].
#3 Why Trinary, the 1+3*5 co-design is a 'wise' investment in the future of computing;
both for new Posopip designs and upgrading Uni-CPU bound systems with two helper CPUs.
#4 How 1+3*5 makes current Artifical Inelligence efforts inefficient;
**** splitting a CPU into pieces is now obsolete, given tomorrow's abundant multi-core wholes!
#5 Why 1+3*5 is a viable design given the r/t QNX power available today with its elegant CPU core libraries
and its r/t network interfaces.
The QNX web site.
#6 How 1+3*5 can capture the interest of tomorrow's innovators who are frustrated
with current SMP systems that use their available CPU cores poorly.
It's like having a 16 cylinder engine that can only fuel and fire several at once at unpredictable times;
and it often sputters or worst, it stalls out fatally, often losing your setups!
Mister-Computer's Long Term Financial Product: www.Fee-mail.org
Fee-mail.org is the name of Mister-Computer's revenue products.
It will be a fee-based email-like system that requires ALL senders
to post a bond for each message that is guaranteed delivered.
The Sender/Depositor get to specify how the postage-bond relates
to the verifiable actions of the receiver.
eg. 5 cents to open and 30 cents more to download/read/complete.
Also, how any Fee-mail.org fees are to be shared.
Normally the remaining unused bond amount is returned to the sender,
less the Fee-mail.org handling fee; typically 2 to 20 cents; COD's are also accommodated.
eg. If your Fee-mail.org threshold is set to 75 cents; then any message you get
must have a 75 cent or greater bond, or you never see it outside of a rejection summary log.
You can also set your account to harvest the pennies of incoming pings .
Redeeming a ping allows your address to be validated/created/revealed
and setup as a current temporary Fee-mail destination with a 75 cent threshold.
Only Prepaid Messages Allowed!
Fee-mail.org is composed mainly of temporary user accounts whose lives were wedded to the user's intent.
Fee-mail.org protocols auto-filter out whatever the user deems unwanted; based on bonded trust.
Controlling SPAM
Spamming is vanquished/controlled in that one is getting paid for a voluntary transaction.
A Real Public Net Address free of SPAM
---- One can now have a real public net address free of junk mail.
---- A public address with an inherent "call screening" shield that is monetarily based!
Fee-mail runs in the 1+3*5 environment under the Posopip O/S's CPU Trinary.
eg. senders must buy a temporary stamp that has cash value to you the receiver.
The received amount can be kept for whatever reason!
Friendly parties use Rebates contained in the message acknowledgment.
-----side effect: every prepaid Fee-mail.org Message gets acknowledged in a timely fashion.
The Fee-Mail prototype effort
Our prototype Fee-mail application will be based on cash value Bitcoins or postage credits
which are redeemable on-line in the holder's currency.
Because the receiver performs the desired steps in the depositor's order,
Fee-mail can deliver accurate product fulfillment at a fixed cost.
eg. 30 cent stamp as 2 cents for Fee-mail handling, 3 cents to for recipient to open/read/consider the offer,
and a 25 cent cash reward upon returning the completed offer/survey/poll.
Table of Contents
This was an architectural system designed for users; not programmers.
The Key Ideas in this revolutionary design are having three independent parts for the solution,
instead of just the traditional 'ONE' .Think of a Supervisor/Guard that watches and supervises
two workers, insuring the fidelity and independence of the solutions.
Since the guard or watcher CPU is mostly static and non-interruptable,
its integrity is nearly impossible to compromise in that every phase of its existence
is independently audited and time stamped while it loops through its cycle.
Almost all modern security problems and system errors occur because there is only one
shared CPU or O/S available to generate the solution.
Security is compromised easily by any one or more of the cpu threads/tasks.
There is no sure way to detect such problems when they occur as they are usually quite unnoticeable
in the noisy environment of most multi-threaded implementations.
Another analogy is the reliability of a single-engine automobile vs.
an engine-per-axle implementation; especially when the vehicle is a multi-axle one.
Which is more robust, able to complete the journey if engine problems developed?
Remember this was a journey of trust, that carried YOUR valuables for a short period of time,
until the correct delivery is made or time runs out.
"Application Design-to-Completion" becomes faster and less costly
in that, the Trinary's 3 CPUs usually mirror the boundaries of the problems being solved.
No need for complex solution Algorithms that must be combined around a single point of execution.
Fee-mail allows the creation of a short-term marketable "Transaction TRUST" message;
this design provides both means and avenues for one's financial dealings; via its chain of verifiable steps.
Table of Contents
This material has two overlapping themes; detailed technical descriptions coupled with relevant
business notes. The intended audience for this material are venture capitalists, investors and the
experts they will consult to judge the overall design feasibility of this 16 CPU scheme.
What makes this 3 CPU architecture unique is its being able to complete the job
with 100% reliability to both the Designer's and User's Intent!
Due to the inherent technical nature of this material, this "bottom-line" summary
is presented to allow a context of evaluation to those who are not familiar with such matters.
Here is a minimum of what will become available for this R&D investment.
1. A fixed time schedule of five years max; with working on-line capabilities after three years or less.
2. A prototype coupon system as a working application that has the potential to earn back the initial investment.
3. A generic reliable ADVERT friendly, SPAM controlled fulfillment system using prepaid postage.
4. Bondable Security Guarantees will be available for all properly configured JOBs via a postage surcharge.
5. A generic single CPU life-cycle extender vehicle that will be marketable to an audience of presently bound systems.
6. Many new ways to design parallel applications; some will be marketable to Commercial and Military needs.
------ eg. 5 r/t seat(s) for a 5 seat Control system for a modern Commercial Airliner.
------ 1. Pilot seat, 2. Copilot seat, 3. Navigator seat, 4. Systems/support seat and 5. Spare Seat.
7. A share of the Patent, License and FEE-MAIL.ORG postage fees, based directly on a one-sixth equity stake.
A Future Labor / Fan Pool
These fans/users will evolve into a unique new power class .
A near perfect future audience, to populate and design this new way of parallel processing
in our increasingly computer literate society.
This next "computer smart" audience will be hungry for select current prepaid adverts/solicitations.
Think of them getting r/t tweets on their cell phones from their "YNET Operator Class" home system
that earn them Credits | Bitcoins by running a local "1+3*5 Backbone Network" node in our proprietary franchise system.
Table of Contents
LINKS
This WEB page address: "http://mister-computer.net/13x5/13x5sum.htm"
author: RD O'Meara Oak Park, IL.
Email to:
Here is my published article about the first Western Union computer network traffic generator, TPUT.
Neutrino® RTOS Secure Kernel v6.4.0 has been certified to the stringent security requirements of the Common Criteria ISO/IEC 15408
Evaluation Assurance Level 4+ (EAL 4+).
My interests range widely. Here are some published papers concerning my Physics & Mathematics Insights.
A Monopole Aether Theory: A Classical model of the Aether based on paired Monopoles.
5SPACE : "Stable Particle Masses mapped by (N/2)^5, N=1 to 22"
JID's SLOPE: The Universal Slope of Volume,
both Mathematically and Physically being the Rydberg constant of 1.0973~!
Primes3D: A Construction Proof of Prime Numbers having a cubic Nature.
Short proof of Fermat's FLT: A proof based on power sequences infinite transcendental Logs.
10OCT2012